
I made a file copy thing
- 6th March 2021TLDR: I made a super fast (much faster than cp) command line copy program, with a nice progress bar. The implementation dives into some interesting bits of low level async I/O on linux.
wcp is a file copying experiment I've been working on for the past while. Really, it's an excuse to try out io_uring, a relatively new asynchronous I/O system on linux.

wcp in action
If you're unfamiliar with async I/O, it allows you to queue up reads and writes to run in the background, and check back later to see if they're done, without having to wait before you start doing other things (like submitting even more requests). This ain't no fancy pantsy high-level javascript event loopy memory safey framework though. It's a ring buffer in memory shared directly with the kernel, and you're responsible for reading and writing the right things at the right time. Luckily the io_uring authors wrote a handy library that eases some of the pain of this.
I've been wanting to try my hand at a file copying program for ages - it always confused me that my options for getting a progress bar for a command line copy were so slim. There's been rsync --info=progress2 for a while now, but I'll be honest, I have no idea how to read that output.

What even is this?
So, when I read about io_uring, I figured it was an excellent opportunity to kill two birds with one stone. I set out to match native cp's performance, and provide a nice progress bar, with some decent ETA (estimated time remaining) calculation. What I did not expect, was to significantly beat cp's speeds. I figured it should be close to, if not at, the limit for file copying performance. And people do always say cp is a bit faster than rsync. In the end, I got something that (disclaimer: works on my machine) is quite a lot faster than cp:
20 512MiB files
cp 8.44s, 1213.38 MiB/s
rsync 17.26s, 593.33 MiB/s
These numbers are from a Samsung SSD, I doubt there would be much gain on a spinning metal disk, but I don't have any around anymore to test on.
Implementation notes
ETA calculation
The way the ETA calculation works is pretty interesting IMO. We measure the speed periodically in a separate thread that is devoted to displaying the progress bar. The current speed is estimated by looking at the amount of bytes copied now, and comparing it to the amount of bytes that had been copied 45 seconds ago.

There is an xkcd for everything
This works pretty well, but the problems arise when you have a scenario like the following: You've been copying a bunch of large files, and your current speed estimate is high. Most of your remaining files, however, are small. Small file copies are dominated by the overheads of opening and closing the files, and various bookkeeping around the actual copy. This means, if we use our current speed to estimate how long it will take to copy the remaining files, our estimate will be way too low. The estimate will also swing around wildly depending on what size files we are processing right now.
I attempted to solve this by conceptually splitting the stack of files to copy into two piles: big and small. A file is "big" if it's over 5KiB, and "small" otherwise. I keep track of the remaining "copies" (a piece of a file) for big and small files separately. Every time a copy chunk completes, I check its size. If it's big, I decrement the "bigFilesRemaining" counter, and similar for small. I also push the big/small status of the copy into a fixed size bitset. This means that at any given moment I can tell:
- What my speed is now
- How many of the last N files I copied were big, and how many small
- How many big and small files I have left to copy
What I do with this information, is that every time I calculate my speed, I add it into a rolling average. But there is not just one rolling average, there are actually eight. If the last 8 copies that completed were all small, the "big" count is zero, so I add my speed into the first rolling average bucket. If four were big, and four were small, it goes in the fourth bucket. Conceptually, the first bucket represents 0% big files, the fourth 50%, and the eighth 100% big. I can then look at the ratio of big/small in the remaining files left to copy, and use that to decide which bucket represents the best estimate of the speed for my total set of remaining files.
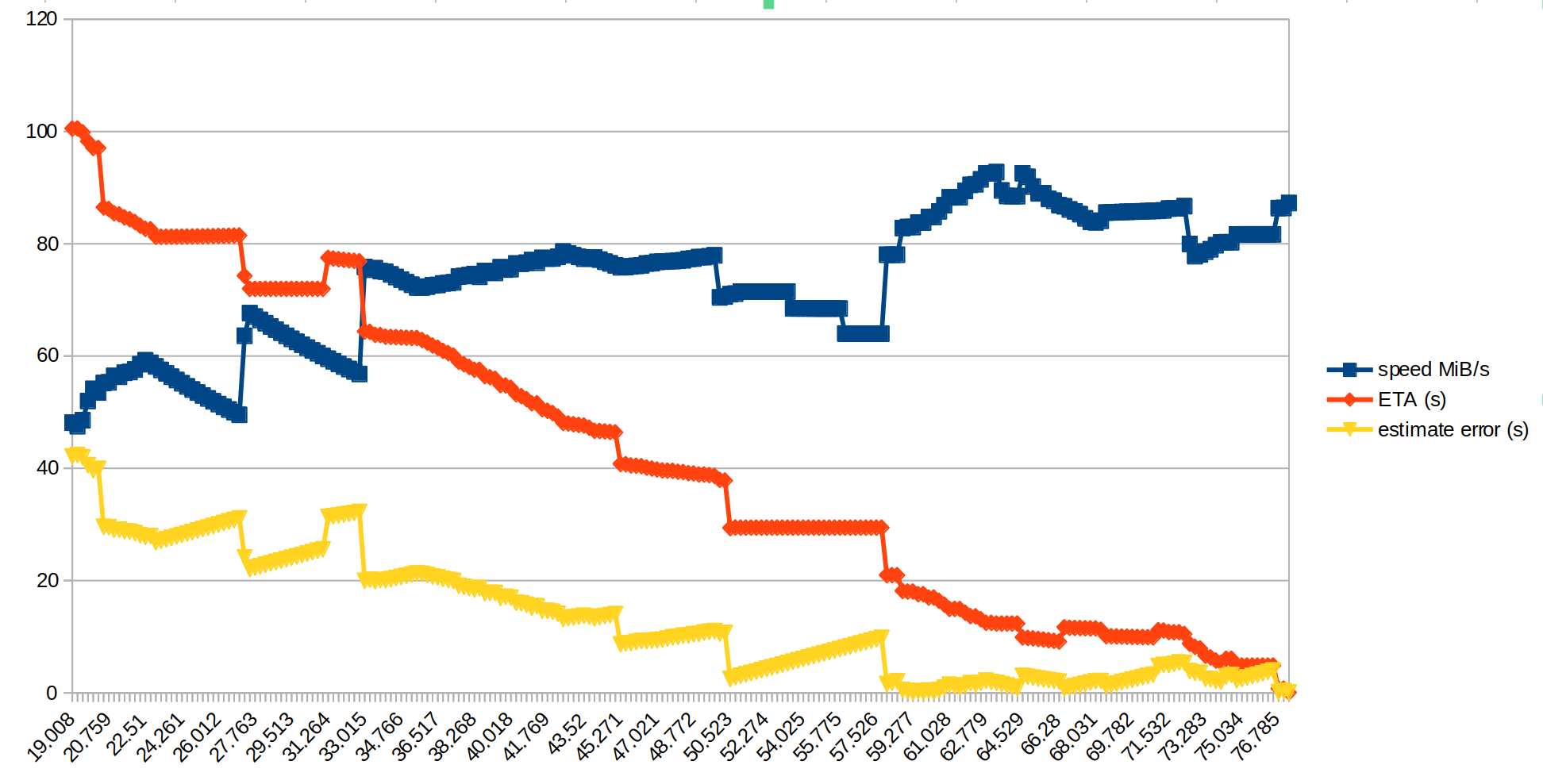
Crude graph of ETA error over time, copying an ~6GiB directory of mixed size files over nfs
This approach seems to work out pretty well. In the graph above, the error in the ETA (the difference between the ETA we predicted at that point, vs the actual finishing time) drops to about 20 seconds after about 30 seconds have elapsed.
asynciness
There are a few parts to a file copying program - we need to:
- Iterate the source folder to gather a list of files to copy
- Create the destination folders
- Open the source and destination files
- Copy the data from source to destination
Of these, only the data copying part is currently done asynchronously. The reason for this is twofold: one, that's the part that takes the most time (usually), and two, io_uring doesn't currently support directory operations (enumerate files in directory and make directory). I actually did do some experimenting with adding IORING_OP_GETDENTS and IORING_OP_MKDIRAT opcodes to io_uring, and made a branch of wcp that uses them, but I haven't tried submitting to the upstream kernel (at least not yet, I might do eventually). Also, I didn't see a massive performance gain. Another point is that trying to submit a patch to the kernel is pretty intimidating :v
Discuss on Hacker News, or Reddit.